Media Analytics & Hyper-Media Services
This article seeks to illustrate ‘human centric web’ and ‘knowledge banking’ considerations (and broader capabilities) relating to media analytics and the production of ‘verified’ media discovery & use related information services.
NB: The intepretation of this document requires study of the broader ecosystem.
google “define media”
The world of digital media incorporates an array of use-cases that range from very high-stakes, through to relatively low-stakes. One of the problems in seeking to address the high-stakes use cases, is that the technical means to perform legitimate media production tasks often forms relationships to other high-stakes use cases; that both relate to wrongdoings society should be protected from; and, highly-sensitive & personal aspects to life.
Broader, more sensitive considerations
(ie: protection of children)
I am very much aware of some of the highest-stakes, use-cases. This article will make an attempt to articulate methodologies that can be employed to solve some of those problems; whilst making broader use-case illustrations.
As is the case with all of my work, the knowledge banking ecosystem is designed to support domestic law-enforcement capabilities, and through that lens Inter-jurisdictional activities that are cooperatively undertaken. Through that lens; consider that (structured) data relating to civilians,
- Is designed to be stored in relation to domestic (citizen centric — or human centric) ‘choice of law’ & governance.
- Operated on a ‘fiduciary’ knowledge banking platform; that would be required to support both ‘data retention’ and lawful access support; and,
- Facilitate lawful requests made by agencies, whilst acting in the interests of their account holders more broadly.
With this in-mind, noting the ability to comprehend this document is coupled with the assumption that prior articles have been reviewed;
This document will attempt to address a few use-cases that relate to ‘media’.
(TV &) Media industry informatics
I’ve previously written about my work in the media field, in an article that seeks to address systemic creative sector issues, in a manifestly blunt way. This article should help to articulate background understandings & prior art.
Therein; The HbbTV specification, which is the international standard for hybrid TV most commonly known as ‘freeview’ (or freeview plus), support TLS certificates; and should in-turn support URIs in TLS certificates as a means to curate personalisation and interactivity with (free) TV Services. As such, this fits into the broader IoT related use-cases described here, and by extension also — how that can be thought of, in public event related use-cases.
Increasingly Apps are used to support Hybrid TV services, whereby similar considerations / technical processes — can be employed.
Media Governance frameworks
Media Production, curation, search and ‘sanitisation’ practices are in-turn able to be improved through the use of media processing and articulation of ‘metadata’ attributes that can articulate content based attributes as are embodied within the media artefacts.
Traditional approaches have undertaken these service-orientated capacities for a long time; but have done so, using proprietary processes that are not easily made scalable, requiring proprietary software licenses and related software infrastructure. Examples include; by category,
AUDIO
- Sonix: Sonic (invite link) provides 30 minutes free.
- Trint also provides 30 minutes free.
- SpokenOnline also provides 30 minutes free.
Image / Video
- ClarifAI is a service that identifies the objects
- Google cloud vision (wp plugin: https://github.com/amirandalibi/perception )
- Amazon rekognition (Wp plugin: https://wordpress.org/plugins/wp-rekogni/
- cloud sight
- Kairos noting, they’ve got a good comparison guide
- Affectiva
- Cognitec
- betaFaceAPI (Designed for faces)
Text based services should also be considered in relation to translations; as may be obtained from either unstructured text or media analysis, as to perform entity relations (as exampled by redlink here) or sentiment analysis (as exampled here).
It is important to note, the google cloud API, amazon cloud APIs, IBM Watson APIs and similar; have an array of ever expanding series of capabilities on-offer as their AI tooling is continually developed.
Whilst this offers a series of capabilities today, the business systems approach is limited in its practical offering; that in-turn leads to many subsequent issues, that are less flexible, less ‘enabling’ than possible alternatives; built into, the framework / ecosystems considerations of a human centric / knowledge banking industry, based approach.
Therein, the consideration is that it is desirable to migrate away from this commercially available API based approach to an alternative, functionally developed alternative; that can in-turn make use of existing APIs to support it.
The “Human Centric Web” Semantic Web approach
The illustrated example i’ll use, will start by communicating how it is the EU project — Mico-Project, that powers the afore linked ‘redlink’ platform — works; and how it is this platform fits into the broader ecosystem.
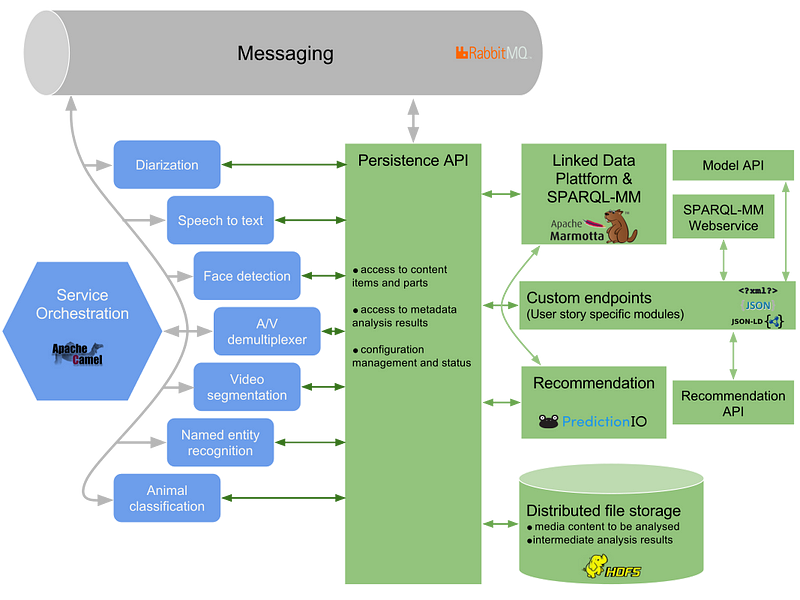
The Mico-Platform project produced / built upon, apache platform technologies; namely incorporating, the Marmotta, the apache linked-data platform project; and Stanbol, the apache semantic inferencing project.
Underneath this content ecosystem are a set of ‘analytics cartridges’ or ‘extractors’; that have initially been produced to do such things as,
animal detection, textual analysis, video quality, temporal, segmentation, automatic speech recognition, speech-music discrimination, face detection, audio tampering detection (nb: source link)
What the platform methodology then enables, is the ability to perform queries using a variation of SPARQL they called SPARQL-MM.
What this in-turn demonstrates, is the ability to produce structured notations in relation to object recognition, or concept assertions and similar; as to be exported in a format that supports SPARQL (and SPARQL-FED) queries.
Qualifying URIs
The platform method shares the ecosystem constituents to other semantic web tools & projects, which are in-turn uplifted through the additions made with the credentials and verifiable claims works, which in-turn relate to the suggested pathways to technically support permissive commons. Therein, the conceptual / material opportunity; is to define the means for media assets to be identified and maintained in relation to the moral rights of the data-subject, as is embodied within the object. Upon that basis, the means to decentralise discovery and semantic inferencing capabilities; in relation to objects, becomes part of what is made able to occur, in connection to business rules that may include (but not be limited to) micropayments and other rules.
Thereafter; one such series of use-cases relates to ‘naturalised interfaces’ which incorporates both biometric identifiers alongside others provided via WoT (IoT) infrastructure frameworks and software structures.
Therein; the simplest example is AR head-mounted displays.
The intent was illustrated in a slide pack produced some years earlier,
My A.I. & A.R. Semantics presentation from 2016. Noting ‘solid’ is now led by Tim Berners-Lee’s Inrupt
Magic leap is one of many emergent producers of innovative human-interface-devices that are significantly different to traditional smartphones, laptops, tablets and PCs; sharing similar technical requirements to smart cars & robots.
Relationships to a “Permissive Commons” approach.
Brian Wassom has produced a book reviewing emerging issues called Augmented Reality Law, Privacy, and Ethics: Law, Society, and Emerging AR Technologies; and discussions between myself and dave lorenzini since 2017 (Dave was previously instrumental to the keyhole (google earth) project); continues to discuss how emerging projects such as open-standards for AR can address some of these underlying issues, in a fit and proper way. Whilst this has been on the agenda for sometime; the descriptive overview of how to do so, is thought to be formed through the means now described on medium.
Therein also — are considerations that can be made about the advent of dynamic AI produced audio/visual media.
In 2016, in an effort to convince web-elders that they should get onto the job of ensuring web-services of the future were made as to provide them, the ability to define their own avatar; rather than someone else programming it later on, some research was performed on the deepfakes issue & related considerations.
One of the more difficult tasks relates moreover to the audio, rather than the video itself.
It is deemed to be highly likely, the technical issues relating to how these works are able to be rendered in a manner that may be very hard to distinguish, as a machine-generated representation, has in-turn an array of practical & legitimate use-cases; alongside others, that are at a minimum morally wrong if not otherwise a breach law or exploitation of the lack of it.
If people are not granted ownership over their own biometric markers; the ability to bind law to representations made in media assets, will be very hard.
Technically, these emerging capabilities offer the means to improve lip-sync for film, tv and media that is recorded in a foreign language; with alternative language dialogue available via post-production (or live) encoding method.
The ability to produce animated bots, whether for purposes that support the means for someone to engage in an AI representation of Einstein, a customer service bot; or new interactive forms of hypermedia content that may offer personalised experiences in relation to a broader narrative & fictional world.
Yet this is distinct to the many other use cases that may exist.
From promotional videos seeking ‘consumer’ engagement, by generating personalised messages that may in-turn associate to knowledge that can be found about that particular person; or the means for someone to obtain sufficient images or video of a person, to use in some sort of VR Fantasy or to mislead and deceive others about what it is that person or persons, have said, say, or is represented in a media format without their express consent, to be “shown to think”, in-turn forming distorted interference patterns as may be implicated by causality to consequential wrongdoings by observers.
In Conclusion:
The solutions framework illustrated by my WebCivics medium articles, when applied to how this problem may be solved; seeks to form through the means of a knowledge banking industry (and related legal structures) the means for persons to beneficially own the use of attributes relating to their character & personhood.
Whilst the laws that are required as to support this morally founded consideration, would need to be curated in a manner that takes into consideration the role of various groups, agents and agencies; the underlying principle, is that the ecosystems methodology is intended to support the means for law to direct what is considered to be fair, reasonable, proportionate and appropriate; whilst the technology ecosystem, is designed (through a knowledge banking industry) to support the privacy / dignity preserving needs of actors & their rights to assert how it is their character or the representation of them; is made available to others; particularly with respect to commercial circumstances.
(whilst providing support for many other use-cases, more broadly).