Tech for Permissive Commons
How is a ‘permissive commons’ system made to work, and what does it provide, technically?
Background
I have previously written a less-technical article on permissive commons that can be found here. This is part of an overall ecosystems approach that is intended to forge a ‘human centric’ informatics environment.
The difference between traditional ‘silo’d’ approaches and this ‘human centric’ approach is in the provision of safe & secure informatics environments, where the data collected about people and in relation to people; is stored on behalf of those people.
This methodology is an alternative to the already well developed ‘persona ficta’ centric alternatives where information is stored in relation to web-services operated by a website provider in the more traditional sense..
To achieve an outcome where people can beneficially ‘bank’ their own data and operate its use with applications, systems need to use decentralisation methods in a different way to how it is generally done already.
Existing sites (like facebook, youtube, google, etc.) are distributed across a multitude of servers across the world as to make their websites work, their decentralised systems still centralise authentication, database management and commercial / legal business systems.
In the alternative method that is sought to be achieved by a human centric web methodology; these business functions become technically decentralised as to bring to effect a means where the extension of agency (ie: personal agency) becomes inclusive to both data, and the repercussive informatics events that are derived as a consequence of personal expressions of thought.
To achieve this outcome, a different set of tooling is required.
Whilst these alternative systems are designed to support all forms of legal actors (and their tools); the consequential technical design element that is sought to be achieved by way of Permissive Commons, relates to the functional requirements of seeking to obtain knowledge about the world in the form of structured data and to make use of that within private settings.
It is difficult to find images that describe how this can be made to work within a knowledge bank that supports inforgs. Nonetheless, there are many examples of how this sort of technical infrastructure is used in conventional web-based business model backed web-services.
To better support evaluation; I’ll use healthcare informatics as an example. .
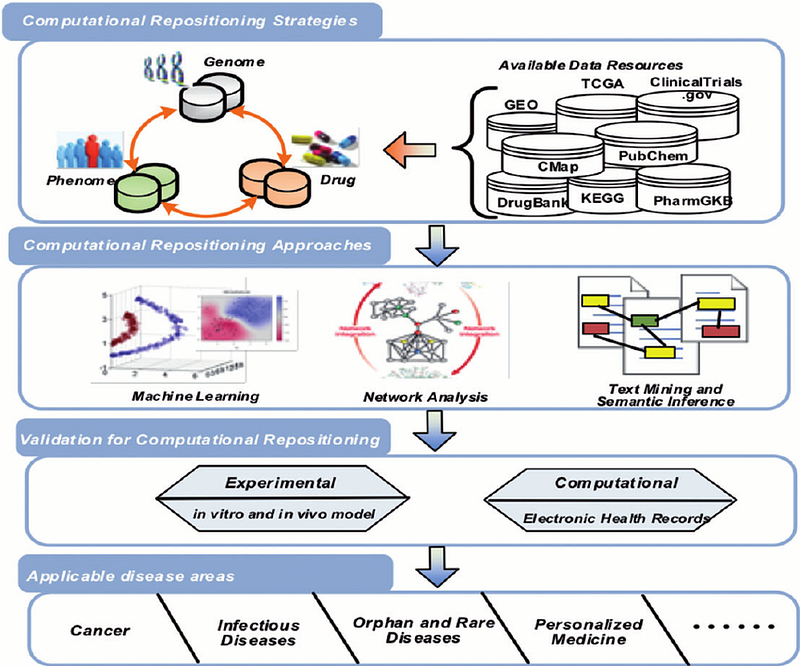
Source: A survey of current trends in computational drug repositioning
Computational Repositioning strategies represents a series of data-sources and related libraries of information, all of which could be different forms of permissive commons.
Therein, societal knowledge that has been produced in many ways, is able to be communicated in a common ‘linked data’ format (or transformed to linked-data, whilst many health-sci systems are in LinkedData and often ‘Open’).
Now for a moment, imagine you’ve got a place to store all the information that relates to your health. Perhaps there is an extraordinary change, and the safest places for personal information are provided by Google, Apple, Facebook and similar. Or perhaps, there’s a knowledge bank that kinda needs, permissive commons (as i continue to explain how, and why).
So, the above image illustrates how there’s a bunch of scientific knowledge about the world, but in-order to make use of it personally generated information, or information generated about a person, needs to be processed in relation to available knowledge in the world to the articulated ‘senses’ transcribed to data, by way of — what i’d call, an inforg. For purposes relating to health; this could include,
Social factors, both those relating to the spread of disease and those relating to behaviours where sentiment analysis could be used to process communications to see if you are happy or sad, and if there’s trends at different times of the day.
There could be dietary considerations, that could review not simply the information about the objects that have been consumed, but also the entire history of the ingredients relating to the production and distribution of those food and beverage objects and information about the make-up of those food-stuffs.
It might also form relational links, so if a few people who ate at one restaurant all get sick at a similar time, this can form part of the inferencing capacities.
Information about exercise, sleep cycles alongside other biosensors & ‘smart things’ like ‘smart toilets’ producing health-data alongside the information created about persons every time the person gets a medical check, test, image or procedure.
The analytics information that helps cameras identify who you are, such as your walking gait could be stored as to analyse for changes that may denote a health problem emerging.
What is Ontological Design?
All of this information needs to be stored in a structured format that is able to be understood by the software processes and systems made able to use it. The term used to define these vocabularies is ontology, which provides electronic record data-structures, that are able to be produced using multiple ontologies.
Traditional approaches brings all of this data into the same ‘silo’ as the provider, but their design practices, relating to why they do so, isn’t necessarily about you.
Anther problem is, that due to real-world issues that do reasonably relate to personal agency and trust; these systems are often incomplete. Considerations such as whether an intimate partner is being intimate with others, and how that may have social-health effects, isn’t part of it. The implications of loosing a job and financial distress, not part of it. The information about whether there is a known environmentally toxic event, not part of it. Not-only do these practical health impacting circumstances, the problem develops a situation where solutions either seek to obtain all the information they can possibly get as to improve the way their AI systems work; or, end-up being /less unreliable.
So, the underlying purpose of decentralising ‘open data’ (note ‘principles’) in a manner that supports the needs of institutional (and other) producers of to employ and rely upon reformulated ‘permissive commons’ informatics products; is about providing the means for their tools to be used by persons in a particular way; that seeks to better support privacy, or moreover, human dignity (and therein, confidentiality).
If couples form agreements about how their relationship works, that’s fine — but it’s not something that needs to be published on facebook. If there are relationship problems that relate to clinically relevant considerations, how could it be dignified to be treated for something else entirely? If information about you and your relationships in the form of your ‘digital twins’ is being used to define you, wouldn’t you want to define in that environment how you treat others with dignity? or is it suggested, that these sorts of consideration, really don’t matter…
Semantic Web technologies are not only used today, but are about the only global ‘patent pool protected’ royalty free method able to power advanced AI.
Whilst health is amongst the highest, of high-stakes use-cases, the principle methodology sought to be employed to produce a human centric web is intended to result in an outcome that is considered ‘safe, for health’.
Permissive commons is intended to provide the means for institutional providers, who have huge server-farm capabilities (something a home-server just can’t do on its own) to get a functional local copy of information from sources across the world; and to then, empower human beings to make use of it without having to necessarily share how they’ve used it or what it says, to anyone unless they’ve defined how they want it to be used for the benefit of others. The only two fragmented elements are that;
A. If anonymised statistical data can be collected and aggregated from a multitude of ‘knowledge banks’ this would be good for research & STEM.
B. Circumstances whereby law provides the capacity to seek specific info.
More broadly; as to recenter the article away from the specificities of health,
The permissive commons framework in-turn considers also derivative considerations relating to other articles and resources that consider the need to have a micropayments standards alongside the work supported by Amanda Jansen on value accounting initiatives; and those of her (/our) works on assessing the qualities of existing DLT solutions.
These works are in-turn was produced to both to support this scope of works; alongside the means to evaluate biosphere impacts (ie: energy consumption) alongside other attributes that are envisaged to inform the rationale as to why open standards are required.
So; to recap,
Dynamic (semantic) Agents are a form of software agent that makes use of ‘AI’ tools that make use of available data in association to queries, and the rules set-out by someone that defines how the request for information should respond.
The practice method sought by a human centric approach centres upon the means for a natural person to make use of a dynamic agent (ai) for personal use; without being unnecessarily (or so it may be considered due to the advent of a solution) interference by international or corporate desires being injected into the ‘sense making’ methodologies of dynamic agents; and the effects this has on both natural agents, and broader socio-economic systems upon both man-made and biosphere environments.
A key element to how this is thought to be best made to work; is through this concept of ‘permissive commons’ and as the intention of this article; is to illustrate some of the more technical details….
The most basic explanation is: that the informatics assets required for ‘freedom of though’ need to be distributed across the web as a core component of how it is that our cyber environment is made to work.
TECHNICAL INTRODUCTIONS
The concept of permissive commons is built upon the idea of information centric networking approach, that is similar to many DLT solutions in many ways. One technical difference, is that i’m suggesting a standard be produced which is seemingly the domain of IETF.
Permissive commons infrastructure could thereafter, incorporate economic considerations that seek to fund the availability of this ‘content’ or ‘information’ centric networking approach. The rationale being that the core libraries required for enterprise systems as part of the functional requirements for distributing trusted copies of datasets; share similar technical properties to the requirements that exist to support micropayments.
Additionally, the means to provide a means to attribute ‘work’ with fair-payments for workers, alongside attribution, would improve support for international law as may in-turn act to support improved qualities relating to trust dependencies.
The objective, should a protocol be defined as a standards, would be to deliver an opportunity ‘better than bitcoin’, that acts in-turn, to support kindness, human creativity & STEM in knowledge based activities, alongside economics.
Functional Requirements
Linked Data
The methodology MUST support linked-data URIs. This may include DIDs or alternative IANA assigned URI-Schema that would support a similar function.
Version Control
The methodology MUST provide the ability to reference the temporal attribution (version) in addition to the identifier list object (‘most recent’ URI) and provide the means to support inferencing mapping should variations between the two exist.
When actors in a social system are generating data overtime, these events are temporally associated. URIs that refer to resources that are not temporally notated bring about a problem where the definition of that resource can be changed overtime; which in-turn has the effect of changing the semantics
Decentralised
The methodology MUST support the ability to obtain for local use a copy of the informatics datafile for private use in relation to semantic inferencing services; and related functional requirements.
Permissive
The methodology MUST support an array of permissive modalities that range from a single custodian signature to that of a permissive group; inclusive of workflow considerations (roles: ie: draft, unofficial, official, etc.).
Permissions should include considerations about read, write, append, bi-Directional Links, etc.
In many use-cases networked informatics resources need to maintain persistence and shouldn’t be deleted, and is noted in relation to the concept of CoolURIs by TimBL that is summarised as ‘cool uris do not change’
Multiplicity: The means to define a multitude or plurality of ledgers, with a multiplicity of permissive orientations as to produce ‘fit for purpose’ informatics resources.
In-order to support an array of functional considerations, the suggested method would produce a multitude of record ledgers and support distribution of a portion of any one entire ledger.
Records formats should (or could) be ‘subject’ orientated; with attributable records to that ‘subject’ being made available independent of other ‘subjects’ or related records.
An example may be that a device being used to find a toilet, doesn’t need the information about all public toilets in the world; they may only need to get the information about the toilets that are nearby. Operators of infrastructure in Australia are unlikely to reliably require information about toilets around the world, they may just need the information about ones that are located in the geographical region relating to the persons who their services, are serving.
Tamper evidence
Each record should be signed with a cryptographic instrument that provides the means for consumers of those data-files to check provenance & supplier of the record; as does relate to the issuer (or governor) of it. This is required for several reasons; including, providing a means to defend against ‘man in the middle’ AI (content / semantics level) attacks.
Transport
Transport security is a requirement. Cryptographic instruments should be used in a manner that is supportive of KYCC/AML related laws; whilst defending against unlicensed attack vectors / actors.
(by ‘unlicensed’ i mean, unlawful acts by any party inclusive to authorities domestic or international)
Content Payloads (nb: i’ll figure out a better name later).
Content payloads are intended to support semantic informatics structures that are in-turn provided for the purposeful use of a semantic agent in relation to the creation and use of personal documents and related AI functions.
The operational & functional supply of the informatics needs for software applications, requires the software to be able to process the information.
More broadly, the consideration is that much like downloading a copy of a blockchain (or torrent); the distribution of ‘knowledge’ and ‘information’ assets, that are able to be consumed by agents, is considered to be a functional requirement that should be supported by an approach that makes use of relevant (W3C, IETF, etc.) open standards.
These file structures should in-turn also support permissive use structures, which in-turn relates to the functional properties of services provided by knowledge banks. It is ordinarily impossible to ensure a copy of information that is successfully transmitted to another device, is able to be made inaccessible at a later date. Knowledge Banks, on the other hand, would be morally / legally obligated to perform this function; and are able to support queries by way of obtaining the query request, and processing it locally.
Content Object (ICON)
The content payload should be able to be represented as an ICON with a short description, links and other ‘authorship’ related information (ie: inclusive to any license & governance related terms).
Format: SVG (can PNGs support this? Re: packaging, it might be easier to deliver in a HTML wrapper)
Use cases:
- Providing ‘easy to use’ query object co-development
Ie: Sparql constituent of a query representing a search for a person with a particular attribute (gender, etc.). The utility of this is to form constituent sparql query objects that can form facets of a more complex query.
Functionally similar to an openbadge the principle objective is to improve usability and trust related attributes; as graphical, trade markable icons can be used to associate to the provider of a particular dataset resource.
Ie: Australian Bureau of Statistics ( or any other provider) icon & associated information
Permissive Commons — Content Types
- Sparql Queries
- Ontologies
- ‘Open Data’
- Biosphere / Natural World Data-Sets
- Human World data sets (langage, etc.)
- Discovery / ‘information centric’ networking datasets
PERMISSIVE TREE SUPPORT
The GIS (geographical information services) frameworks may incorporate information on a multitude of layers; that are in-turn likely to have an array of custodial relationships with an array of stakeholders.
A towns local government may govern the allocation of the spaces; including those of private property, whilst the utility of private-properties may have many owners overtime, involve real-estate agents; and tenants (those who rent the place and retain rights over the properties use).
Whilst distinct, there are a series of similar ‘ecosystems’ evaluations that occur with all sorts of things in the real-world spaces, places & related things (of both a natural, man-made & artificial ‘cyber’ nature). This in-turn relates informatics structures to governance models, addressability and interactivity between ‘conscious minds’ and things; in a format that forms a multi-modal ‘graph’ nature; with temporal associations.
Perhaps also, another important note may be to highlight the use-case of associations with IoT, software interfaces and other ‘digital twin’ aspects.
Notation Method
Linked data standards & related formats.
For reasons i do not entirely understand, it seems N3 might be the preferred serialisation format; and whilst documentation might focus on that, json-ld and other serialisation formats should be interchangeably supported.
The history of this is that TimBL defined N3 as an RDF Native serialisation (as described in his design notes) but the problem was that developers who were building applications based on a ‘silo’ approach found it hard to grasp. To support RDF uses, particularly for silo’d applications & related services, like search, the means to adapt JSON to support RDF was produced as JSON-LD.
Today, there is alot of JSON-LD & JSON related APIs and services, alongside people who are more easily able to use it. Yet TimBL often remarks his preference for N3, and frankly — i think his a trustworthy guide on the issue.
The other factors worth noting are; a. serialisation formats are interchangeable, as can be demonstrated via Any23. Secondly, as the purposeful design of these ‘permissive commons’ structures are, by association to philosophical design, different to the otherwise well-developed centralised approaches; any additional barriers brought about by using N3 may serve as a reminder for the moral and ethical differences that relate to systems that are designed to support permissive commons structures.
noting also that the json license includes a stipulated term “The Software shall be used for Good, not Evil.” that seems in many ways, far too vague.
Ability to support semantic cryptographic proofs
The concept of ‘semantic proofs’ probably won’t make sense to most; generally, i’m saying that we can form methods to support ‘blockchain like’ functionality, without enormous dependencies on energy consumption as engendered through ‘proof of work’ schemes and formats.
The alternative illustrated therein; is about the use of social-semantics & cryptography in addition to cryptographic proofs. Some examples include zero-knowledge proofs; but all together — there’s experts who know best.
Refining the definition of ‘permissive commons’: illustratively
As illustrated above; if a person has a health problem, the best way to address it is to ensure those involved in the person / patients healthcare; are mutually able to be made aware of what it is that is going on.
This consideration does not extend to people who do not have a need to know.
Whether it be mental health, gynaecological health or the many other fields; the patient should be the curator of who has access to their health information; whilst not being best placed to undertake meaningful actions that can improve health, based upon clinical insights engendered through studies.
Therein; the consideration of ‘permissive commons’ extends to the informatics patterns where select groups are permissively provided use of (point) data materials where required; and in-turn generate data themselves about what it is they did when interacting with that data.
therein also — simultaneously, the means for decentralised ‘data curators’ (ie: knowledge banks) to aggregate records as to render ‘anonymised’ results that can permissively be back-traced to the point data; for the purposes of legal audits (accountability) whilst not breaching privacy, is sought to be supported by these permissive protocol methodologies..
Compiled and component (signed) distributions
Artefact offerings provided by a permissive commons informatics distribution system should offer the ability to GET a compiled version; that incorporates the semantically referenced related datasets, in addition to an uncompiled (smaller) version; that requires GET requests when specified records relating to the dataset are required, but not available locally.
(somewhat similar to some of the above notes)
Example 1: might be that someone gets a parking ticket (or speeding ticket) they want to dispute, and want to use data that is available to create a ‘verifiable claim’ in relation to their lodged dispute.
Example 2: A system requires an ‘offline’ copy, for activities in environments that have poor (or no) access to internet.
EXISTING WORKS
Technically, this proposition shares many qualities of existing solutions; and it is now desirable to get a subject matter expert involved to form the cohesive technical specification, method and proof of concept.
Considerations therein; include,
GIT is a version control software that supports many of the local and networkable requirements; although some elements appear to not be available with existing solutions available today.
The benefit of using GIT is that it’s already built into the vast majority of web servers and is well-developed technology.
BitTorrent (and similar) demonstrates the ability to resource a data-resource and distribute it using P2P techniques. WebTorrent and WebDHT are amongst the ‘family’ of solutions available, worthy of consideration.
- DAT
- IPFS
- Mango (https://medium.com/@alexberegszaszi/mango-git-completely-decentralised-7aef8bcbcfe6 )
- Holochain (as distinct to the company ‘holo’ and its AUTH methodology)
Other Constituent Technology considerations
draft-cavage-http-signatures-10 - Signing HTTP Messages
_Network Working Group M. Cavage Internet-Draft Oracle Intended status: Standards Track M. Sporny Expires: November 15…_tools.ietf.org
Final Notes
What is the intended impacts upon ‘open data’
the intention is to supercharge opendata with modern capabilities
What Business models might this break?
The permissive commons concept is likely to break business models such as;
- Search (ie: google search etc. but not necessarily google)
- Blockchains (crypto currencies)
- Fake News and all the permutations of it (in connection to the broader ecosystem)
- other (TBA).
How would organisational ecosystems define permissive structures?
This is in-part considered by the idea of forming tools for knowledge clouds.
In Conclusion:
The overall instrumental value sought to be achieved with ‘permissive commons’ is to deliver a core ingredient for a knowledge age; whereby the rules for how a society is governed relates to rule of law; and not tech vendors.